
Cloud Computing & Big Data is revolutionizing how we process and analyze vast amounts of information. This technology empowers businesses to unlock hidden insights within massive datasets, driving innovation and efficiency. From healthcare to finance, the applications are diverse and impactful. The seamless integration of cloud platforms with powerful big data tools offers unparalleled opportunities for data-driven decision-making.
This guide will explore the core concepts, technologies, and practical applications of cloud computing and big data, providing a thorough understanding of this transformative technology. We’ll cover everything from the fundamental principles to real-world case studies, equipping you with the knowledge to navigate this rapidly evolving landscape.
Introduction to Cloud Computing & Big Data
Cloud computing and big data are transformative technologies reshaping industries and our daily lives. They represent powerful tools for storing, processing, and analyzing vast amounts of information, enabling unprecedented insights and opportunities. This section delves into the fundamentals of both technologies, their core principles, and their intertwined relationship.Cloud computing provides a scalable and flexible platform for storing and processing data, while big data encompasses the tools and techniques necessary to extract value from that data.
The convergence of these two areas is driving innovation across various sectors, from healthcare to finance and beyond.
Definitions of Cloud Computing and Big Data
Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction. Big data refers to datasets whose size and complexity are beyond the capabilities of traditional data processing tools.
These datasets often require specialized technologies and algorithms for effective analysis.
Cloud computing and big data are definitely hot topics, and they’re closely tied to emerging technologies. These advancements, like AI and machine learning, are pushing the boundaries of what’s possible with cloud-based big data processing. For a deeper dive into these cutting-edge innovations, check out our comprehensive guide on Emerging Technologies. Ultimately, understanding these emerging technologies is crucial for anyone working with cloud computing and big data.
Core Concepts and Principles of Cloud Computing
Cloud computing is built upon several core principles. These include scalability, flexibility, and cost-effectiveness. Scalability allows for adapting computing resources to changing demands, ensuring that systems can handle increased workloads without performance degradation. Flexibility enables tailored solutions for specific needs, allowing businesses to choose the appropriate services based on their requirements. Cost-effectiveness is achieved through pay-as-you-go models, enabling businesses to avoid upfront investments in infrastructure.
Core Concepts and Principles of Big Data
Big data’s core principles center around the characteristics of the data itself: volume, velocity, variety, veracity, and value. Volume refers to the sheer size of the datasets, while velocity encompasses the speed at which data is generated and processed. Variety signifies the diverse formats of data, from structured databases to unstructured text and sensor data. Veracity highlights the uncertainty and incompleteness inherent in big data, requiring careful validation and cleansing procedures.
Finally, value underscores the potential for insights and decisions derived from analyzing big data.
Relationship Between Cloud Computing and Big Data Processing
Cloud computing plays a crucial role in big data processing by providing the necessary infrastructure and resources. Cloud platforms offer scalable storage solutions for big data repositories, allowing for the handling of massive datasets. Furthermore, cloud-based processing capabilities enable parallel data analysis, accelerating the extraction of insights. Cloud services often include specialized big data tools and frameworks, making them a cost-effective and efficient solution for managing big data.
Analogy for Cloud Computing and Big Data Management
Imagine a library managing a vast collection of books (big data). Traditionally, the library would need a large physical space and dedicated staff to handle the books. Cloud computing, in this analogy, is like a digital library with virtual shelves and access from anywhere. The library can easily add new books (data), and readers (analysts) can access and search the entire collection remotely, using specialized tools to find specific information.
Historical Context of Cloud Computing and Big Data Evolution
The evolution of cloud computing and big data has been marked by incremental advancements. Early cloud computing models emerged from the need for shared computing resources, while the increasing volume and velocity of data generation spurred the development of big data technologies. Over time, advancements in storage capacity, processing power, and networking have enabled the seamless integration of these technologies.
Today, cloud computing and big data processing are deeply intertwined, enabling complex data analysis and insights at scale.
Cloud Computing Platforms for Big Data
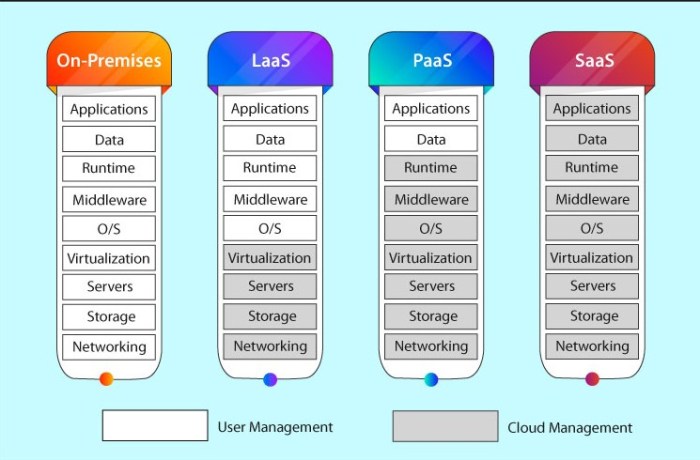
Cloud computing platforms have revolutionized big data processing, offering scalable resources and cost-effective solutions. These platforms enable organizations to handle massive datasets without significant upfront investment in hardware or specialized personnel. This allows for quicker insights and faster decision-making.These platforms provide a range of services, including storage, compute, and analytics tools, tailored for various big data processing needs.
Different platforms excel in different areas, from batch processing to real-time stream analytics. Understanding the strengths and weaknesses of each platform is crucial for choosing the optimal solution for a given project.
Popular Cloud Platforms for Big Data
Several leading cloud providers offer comprehensive big data platforms. These platforms often include integrated tools and services to manage the entire big data lifecycle, from ingestion to analysis. This integration streamlines the process and minimizes the need for complex interfacing between different services.
- Amazon Web Services (AWS): AWS offers a vast ecosystem of services for big data processing, including Amazon S3 for storage, Amazon EMR (Elastic MapReduce) for cluster computing, and Amazon Redshift for data warehousing. The extensive service catalog allows users to tailor solutions for specific needs. For instance, Amazon EMR excels at batch processing large datasets, while Redshift is ideal for analytical queries.
AWS’s pricing is often competitive and flexible, varying based on resource utilization.
- Microsoft Azure: Azure provides a powerful suite of big data tools including Azure Databricks for interactive data analysis and Azure HDInsight for Hadoop-based processing. Azure’s strengths lie in its integration with other Microsoft services, making it suitable for organizations already utilizing Microsoft’s ecosystem. The pricing model is structured similarly to AWS, with variable costs depending on usage.
- Google Cloud Platform (GCP): GCP offers a comprehensive big data stack with services like BigQuery for querying massive datasets, Dataproc for managed Hadoop clusters, and Cloud Storage for data storage. GCP is known for its strong focus on machine learning and AI capabilities, often integrated with big data processing. GCP pricing models are often competitive, with emphasis on pricing per usage and storage tiers.
Key Features and Functionalities Comparison, Cloud Computing & Big Data
Different platforms cater to diverse needs, each with its own set of strengths and weaknesses. The comparison below highlights their functionalities and features:
| Feature | AWS | Azure | GCP |
|---|---|---|---|
| Storage | S3, Glacier | Azure Blob Storage | Cloud Storage |
| Compute | EMR, EC2 | HDInsight, Virtual Machines | Dataproc, Compute Engine |
| Analytics | Redshift, Athena | Azure Synapse Analytics, Databricks | BigQuery, Dataproc |
| Machine Learning | SageMaker | Machine Learning Studio | AI Platform |
Security Considerations
Securing big data in cloud environments is paramount. Robust access controls, encryption, and data loss prevention mechanisms are critical. Regular security audits and compliance with industry standards are essential for safeguarding sensitive information. Using strong authentication methods and adhering to strict data access policies are crucial steps in maintaining data integrity and confidentiality. Moreover, implementing multi-factor authentication (MFA) and regular security updates are essential for preventing unauthorized access.
Big Data Technologies & Tools
Big data technologies have revolutionized how organizations manage, process, and extract insights from vast amounts of data. These tools enable businesses to uncover hidden patterns, trends, and correlations that would otherwise remain undiscovered, leading to improved decision-making and strategic advantages. The diverse range of technologies available cater to various needs, from data storage and processing to advanced analytics and visualization.
Popular Big Data Technologies
A multitude of technologies are available for managing and analyzing big data. These technologies differ in their strengths and weaknesses, making them suitable for various tasks. Choosing the right tool depends on the specific needs and characteristics of the data being processed.
- Hadoop: A framework for storing and processing massive datasets distributed across clusters of commodity hardware. Hadoop’s strengths lie in its ability to handle large volumes of unstructured and semi-structured data. It uses a MapReduce programming model for parallel processing, enabling efficient data analysis. Use cases include log processing, web indexing, and social media analytics.
- Spark: A fast and general-purpose cluster computing system. Spark excels at iterative algorithms and in-memory processing, which drastically reduces processing time compared to Hadoop. This speed advantage makes it well-suited for machine learning applications, graph processing, and stream processing. Examples include fraud detection, recommendation systems, and real-time analytics.
- NoSQL Databases: A family of non-relational databases designed for handling massive, unstructured, and rapidly changing data. NoSQL databases offer flexibility and scalability that relational databases often lack, making them suitable for applications requiring rapid data ingestion and high availability. They are commonly used in applications like social media platforms, e-commerce systems, and IoT data management.
Interoperability and Integration with Cloud Platforms
Cloud platforms offer seamless integration with big data technologies. Cloud providers offer managed services for Hadoop, Spark, and NoSQL databases, simplifying deployment and maintenance. This integration reduces operational overhead and allows organizations to focus on data analysis.
- Amazon EMR: Provides managed Hadoop clusters on Amazon Web Services (AWS). This service allows users to easily deploy and manage Hadoop clusters, reducing the complexities of infrastructure management. It enables users to run a wide range of big data applications.
- Google Cloud Dataproc: Offers managed Spark and Hadoop clusters on Google Cloud Platform (GCP). Similar to AWS EMR, it simplifies the process of deploying and managing big data clusters. It provides tools for data ingestion, processing, and analysis.
- Azure HDInsight: A managed big data service on Microsoft Azure. It provides a platform for deploying Hadoop, Spark, and other big data technologies. Azure HDInsight enables organizations to perform various analytics tasks within the Azure ecosystem.
Efficiency and Scalability Comparison
The efficiency and scalability of big data tools vary significantly. Hadoop is well-suited for batch processing of large datasets, but can be slower for iterative tasks. Spark’s in-memory processing capabilities make it faster for iterative algorithms and stream processing. NoSQL databases provide high scalability and flexibility but may lack the structured query capabilities of relational databases.
| Technology | Efficiency | Scalability |
|---|---|---|
| Hadoop | Good for batch processing | Highly scalable |
| Spark | Excellent for iterative and stream processing | Highly scalable |
| NoSQL | High for specific use cases | Highly scalable |
Data Warehousing and Analysis
Big data technologies are essential for building data warehouses and performing advanced analytics. Hadoop and Spark can be used to process and load data into data warehouses. NoSQL databases can store and manage the massive datasets required for these warehouses.
Data warehousing with big data technologies allows for comprehensive insights into historical trends and future projections.
Data Storage and Management in the Cloud
Cloud storage solutions are crucial for managing and storing the vast amounts of data generated in big data applications. These solutions offer significant advantages in scalability, cost-effectiveness, and accessibility compared to traditional on-premises storage. Choosing the appropriate storage model is vital for optimizing performance and cost in big data environments.
Data Storage Options in Cloud Platforms
Cloud platforms provide a range of storage options tailored to different data types and use cases. This flexibility allows businesses to optimize storage costs and performance based on their specific needs. Understanding the various options available is paramount for selecting the ideal solution.
Storage Models
Cloud storage solutions employ diverse storage models to cater to different data access patterns and application requirements. Each model offers unique characteristics impacting performance, cost, and data access methods.
- Object Storage: Object storage stores data as objects, each with metadata describing its content. This model excels in handling unstructured data, such as images, videos, and documents, due to its scalability and flexibility. Object storage is highly cost-effective for large datasets because it scales automatically as needed. AWS S3 and Azure Blob Storage are popular examples.
The scalability of object storage allows for efficient management of massive datasets. The cost-effectiveness comes from paying only for the storage used.
- Block Storage: Block storage is organized in blocks of fixed size, ideal for applications requiring random access and high I/O performance. It is often used for databases and virtual machines needing fast access to data. Block storage is typically associated with high performance and is frequently employed for applications demanding rapid data retrieval, such as those in high-frequency trading.
The speed of block storage makes it suitable for demanding applications.
- File Storage: File storage manages data in files, similar to traditional file systems. This model provides a familiar interface for applications that already work with files. It is often chosen when working with structured data. File storage is frequently used in conjunction with applications that are accustomed to working with files. It is a common choice for applications that have a familiarity with traditional file systems.
Scalability and Cost-Effectiveness of Cloud Storage
Cloud storage solutions demonstrate remarkable scalability, adapting to fluctuating data volumes. This adaptability is essential for big data applications, where data sizes can vary considerably. Cloud storage solutions offer cost-effectiveness by charging based on usage. This pay-as-you-go model allows organizations to control storage costs, avoiding overspending.
Examples of Storage Models in Big Data Applications
Different storage models are employed in various big data applications.
- Object Storage for Data Warehousing: Object storage is well-suited for storing the large volumes of data associated with data warehouses. The scalability and cost-effectiveness of object storage make it a suitable choice for storing historical data and conducting data analysis.
- Block Storage for Data Intensive Workloads: Block storage is a preferred option for applications requiring high-performance data access, such as large-scale data processing. This storage model’s speed and efficiency are ideal for applications requiring rapid access to data.
- File Storage for Collaborative Data Analysis: File storage is commonly used for collaborative data analysis where users need to share and work with files containing structured data. This facilitates collaboration and efficient data sharing among team members.
Data Backup and Recovery Strategies in Cloud Environments
Cloud platforms offer robust data backup and recovery strategies, ensuring data availability and minimizing downtime. These strategies include automated backups, disaster recovery solutions, and data replication. Implementing these strategies is essential to minimize data loss and ensure business continuity.
Data Processing & Analytics in Cloud
Cloud computing provides a powerful platform for processing and analyzing massive datasets, often referred to as big data. This capability enables organizations to extract valuable insights from their data, driving informed decision-making and optimizing various business processes. The flexibility and scalability of cloud environments are particularly well-suited for handling the ever-increasing volume, velocity, and variety of data generated today.Cloud-based data processing solutions allow for the execution of complex analytical tasks, from simple aggregations to sophisticated machine learning algorithms, all within a dynamic and cost-effective environment.
This approach significantly reduces the need for substantial on-premises infrastructure investments, enabling businesses to focus on achieving their analytical goals.
Various Methods for Processing Big Data in the Cloud
Different approaches to processing big data in the cloud are available, each suited for specific types of analyses and workloads. Batch processing, stream processing, and interactive querying are prominent examples. Batch processing handles large datasets in predefined stages, ideal for tasks requiring extensive calculations. Stream processing, in contrast, analyzes data as it arrives in real-time, useful for applications demanding immediate feedback.
Interactive querying enables users to explore data and retrieve specific information quickly, suitable for ad-hoc analysis.
Data Transformation and Manipulation Techniques
Data transformation and manipulation are critical steps in preparing data for analysis. These techniques involve cleaning, converting, and restructuring data to ensure its quality and consistency. Common transformations include data cleaning to remove inconsistencies, data type conversion to ensure compatibility with analytical tools, and data normalization to improve data integrity. Data aggregation and summarization can also be used to simplify large datasets for easier analysis.
Furthermore, data deduplication, imputation, and feature engineering enhance the quality and usability of data.
Leveraging Cloud-Based Analytics Tools
Cloud environments provide a wide array of analytics tools designed for specific needs. Tools like Apache Spark, Hadoop, and various cloud-based data warehousing solutions are prominent examples. Apache Spark offers a framework for processing large datasets efficiently, enabling complex analytics, machine learning, and data science tasks. Hadoop, a distributed computing framework, is effective for handling massive volumes of data.
Cloud-based data warehousing solutions provide robust storage and processing capabilities for analytical queries. The utilization of these tools, often integrated with cloud platforms like AWS, Azure, or GCP, significantly streamlines the analytical process.
Building a Cloud-Based Data Pipeline for Big Data
A cloud-based data pipeline facilitates the seamless movement and processing of big data. The steps involved generally include data ingestion, data transformation, data storage, and data analysis. Data ingestion involves capturing data from various sources, while transformation refines the data to meet the requirements of analysis. The data is then stored securely in a cloud-based data warehouse or similar repository.
Finally, the stored data can be analyzed using cloud-based analytics tools, extracting valuable insights. This process is often automated to ensure efficiency and consistency.
Cloud computing and big data are transforming industries, and a key area of application is computer vision technology. Computer vision technology is increasingly used to analyze massive datasets generated by various sources, allowing for faster insights and better decision-making. This powerful synergy between cloud computing and big data is revolutionizing how we process and interpret information.
Optimizing Data Processing for Efficiency and Performance
Optimizing data processing for efficiency and performance is crucial in cloud environments. Techniques like using cloud-optimized data formats, employing parallel processing, and leveraging serverless computing significantly enhance performance. Cloud-optimized formats are designed for efficient storage and retrieval in cloud environments. Parallel processing allows multiple tasks to be executed simultaneously, significantly reducing processing time. Serverless computing automates the allocation of computing resources based on the demands of the task, ensuring optimal resource utilization.
Furthermore, appropriate data partitioning and the selection of suitable algorithms are essential for achieving maximum performance.
Security and Privacy Considerations: Cloud Computing & Big Data
Cloud computing and big data technologies offer immense potential, but they also introduce significant security and privacy concerns. Protecting sensitive data in these distributed environments requires a multifaceted approach that addresses potential vulnerabilities and safeguards user privacy. A robust security framework is crucial to ensure the trustworthiness and reliability of cloud-based big data solutions.
Importance of Security in Cloud Computing and Big Data
Security is paramount in cloud computing and big data environments due to the shared responsibility model. Organizations must understand their specific security obligations, particularly regarding data protection and compliance. The volume, velocity, and variety of data in big data sets amplify the risk of breaches and unauthorized access. Compromised data can result in substantial financial losses, reputational damage, and legal repercussions.
Common Security Threats and Vulnerabilities
Numerous security threats and vulnerabilities exist in cloud computing and big data ecosystems. These include malicious attacks like denial-of-service (DoS) attacks, data breaches, unauthorized access, and insider threats. In addition, vulnerabilities in the cloud infrastructure itself, inadequate access controls, and flawed data encryption practices pose considerable risks. The inherent complexity of big data systems can create blind spots and expose data to attacks that might otherwise be mitigated in simpler systems.
Data Encryption and Access Control Mechanisms for Big Data in the Cloud
Data encryption plays a critical role in safeguarding sensitive data stored and processed in the cloud. Advanced encryption standards, such as AES-256, ensure confidentiality by converting data into an unreadable format. Access control mechanisms, including role-based access control (RBAC), grant specific permissions to authorized users based on their roles and responsibilities. These mechanisms limit access to sensitive data and resources, minimizing the potential for unauthorized disclosure or modification.
Implementing multi-factor authentication (MFA) further enhances security by requiring multiple forms of verification for user access.
Strategies to Protect Data Privacy and Compliance in Cloud Environments
Protecting data privacy and ensuring compliance with regulations like GDPR and HIPAA requires a comprehensive strategy. Data anonymization and pseudonymization techniques can mask personally identifiable information (PII) while still allowing for data analysis. Data loss prevention (DLP) tools can identify and prevent sensitive data from leaving the organization’s control. Regular security audits and penetration testing are crucial for identifying and mitigating potential vulnerabilities.
Adherence to industry best practices and established security frameworks (e.g., NIST Cybersecurity Framework) is also essential for maintaining a strong security posture.
Security Protocols for Cloud-Based Big Data Solutions
Implementing robust security protocols is essential for safeguarding data and ensuring compliance. The following table Artikels various security protocols applicable to cloud-based big data solutions.
| Protocol | Description | Benefits | Considerations |
|---|---|---|---|
| Secure Sockets Layer (SSL)/Transport Layer Security (TLS) | Encryption protocols for secure communication between clients and servers. | Ensures confidentiality and integrity of data in transit. | Requires proper configuration and regular updates to maintain effectiveness. |
| Virtual Private Cloud (VPC) | Creates a private network within a public cloud environment. | Provides enhanced security by isolating resources from the public internet. | May require additional configuration and management compared to public cloud resources. |
| Identity and Access Management (IAM) | Manages user identities and access privileges to resources. | Controls access to data and systems based on user roles and permissions. | Requires careful planning and implementation to avoid security gaps. |
| Data Loss Prevention (DLP) | Tools that identify and prevent sensitive data from leaving the organization’s control. | Helps in meeting regulatory compliance requirements. | May require significant investment in deployment and ongoing maintenance. |
Case Studies and Real-World Applications

Cloud computing and big data are transforming industries globally. Businesses are leveraging these technologies to gain valuable insights, improve operational efficiency, and enhance customer experiences. This section presents compelling examples of successful implementations, highlighting the specific use cases, benefits, challenges, and lessons learned.
Retail Industry Use Cases
Retailers are increasingly employing cloud-based solutions for enhanced customer engagement and operational optimization. A key example involves a large clothing retailer utilizing big data analytics to personalize product recommendations. By analyzing customer purchase history, browsing patterns, and demographics, the retailer can predict individual preferences and tailor recommendations. This personalized approach leads to increased sales and customer satisfaction. Further, the cloud infrastructure enables scalability, supporting peak demand during promotional periods.
Healthcare Sector Applications
Cloud computing and big data are revolutionizing healthcare. A prominent example is a hospital system that uses big data to improve patient outcomes and optimize resource allocation. The system collects and analyzes patient data, including medical history, lab results, and treatment records, to identify patterns and trends. This analysis allows healthcare professionals to proactively address potential health issues and personalize treatment plans, ultimately improving patient care.
This also facilitates faster access to critical information, enabling quicker diagnoses and treatment.
Financial Services Implementations
Financial institutions are increasingly leveraging cloud-based platforms for fraud detection and risk management. A noteworthy example involves a bank using big data analytics to identify fraudulent transactions in real-time. By analyzing transaction patterns, locations, and customer profiles, the system can flag suspicious activity, preventing financial losses and safeguarding customer accounts. The scalability of cloud infrastructure is crucial in this case, as the volume of financial transactions can fluctuate significantly.
Table: Summary of Use Cases and Benefits
| Use Case | Company/Industry | Specific Benefit | Challenges Faced and Solutions |
|---|---|---|---|
| Personalized Product Recommendations | Large Clothing Retailer | Increased sales, improved customer satisfaction, enhanced marketing ROI. | Data volume and velocity required significant cloud infrastructure scalability. This was addressed by adopting a serverless computing approach. |
| Improved Patient Outcomes | Hospital System | Proactive health issue identification, personalized treatment plans, faster diagnosis, optimized resource allocation. | Data security and privacy concerns were mitigated by implementing robust encryption and access control measures. |
| Fraud Detection and Risk Management | Bank | Reduced financial losses, enhanced security, improved customer trust. | Maintaining real-time processing capabilities while handling massive transaction volumes required a robust cloud-based architecture. This was achieved through a hybrid cloud deployment. |
Future Trends and Developments
The landscape of cloud computing and big data is constantly evolving, driven by advancements in technology and increasing demand for data-driven insights. Emerging trends are shaping the future of data management and analysis, impacting how organizations store, process, and derive value from massive datasets. These trends present both opportunities and challenges, necessitating a proactive approach to adaptation and innovation.
Emerging Trends in Cloud Computing and Big Data
The field is experiencing rapid evolution, with several key trends reshaping the way data is handled. These include the increasing adoption of serverless computing, the rise of edge computing, and the growing importance of artificial intelligence (AI) and machine learning (ML) in data analysis. These advancements promise significant improvements in efficiency, scalability, and the overall value derived from data.
Potential Impact on Data Management and Analysis
These evolving technologies are poised to fundamentally transform how data is managed and analyzed. Serverless computing enables more agile and cost-effective deployments, while edge computing facilitates real-time data processing closer to the source. The integration of AI and machine learning promises sophisticated insights from data, automating tasks and accelerating decision-making.
Influence of AI and Machine Learning
AI and machine learning are becoming increasingly integrated into cloud-based big data platforms. AI algorithms can automate tasks such as data cleaning, feature engineering, and anomaly detection, dramatically improving efficiency and accuracy in data analysis. Machine learning models can identify patterns and insights in large datasets that would be impossible for humans to discern, leading to more effective predictions and decision-making.
For example, AI-powered natural language processing (NLP) tools can analyze vast amounts of textual data, extracting key information and sentiment.
Ethical Considerations and Societal Implications
The increasing reliance on AI and machine learning in data analysis raises ethical concerns. Bias in algorithms can lead to unfair or discriminatory outcomes, and the potential for misuse of data for malicious purposes necessitates robust security measures and ethical guidelines. The societal implications of these advancements, including job displacement and data privacy concerns, demand careful consideration and proactive solutions.
Data governance and responsible AI development are crucial to mitigate potential risks and maximize benefits.
Future Trends and Their Implications
| Trend | Description | Potential Impact | Ethical Considerations |
|---|---|---|---|
| Serverless Computing | Deploying applications without managing servers. | Increased agility, reduced operational costs, improved scalability. | Potential for increased complexity in debugging and maintenance. |
| Edge Computing | Processing data closer to the source. | Reduced latency, improved real-time insights, increased security. | Potential for increased data storage and management needs at the edge. |
| AI/ML in Data Analysis | Using AI/ML algorithms to analyze big data. | Automated insights, enhanced accuracy, faster decision-making. | Potential for algorithmic bias, data security concerns. |
| Quantum Computing | Leveraging quantum mechanics for computation. | Potentially exponential speedup in complex calculations. | High cost of implementation, limited accessibility. |
| Blockchain Technology | Implementing secure, transparent data management. | Improved data integrity, enhanced traceability, increased trust. | Potential for scalability challenges, complexity in implementation. |
Illustrative Examples of Big Data Applications
Big data applications are transforming numerous sectors, offering valuable insights and driving significant business impact. These applications leverage the power of cloud computing to process and analyze massive datasets, revealing patterns and trends that were previously hidden. By harnessing the cloud’s scalability and cost-effectiveness, businesses can unlock new opportunities and gain a competitive edge.
Healthcare Applications
Healthcare organizations utilize big data to improve patient care and operational efficiency. Electronic health records (EHRs), patient demographics, and treatment outcomes are combined to create a comprehensive patient profile. This data is analyzed to identify trends in disease patterns, predict outbreaks, and personalize treatment plans. Cloud-based platforms enable efficient storage and processing of these large datasets, allowing healthcare professionals to access critical information quickly and easily.
The insights derived from these analyses can inform preventative measures, optimize resource allocation, and ultimately improve patient outcomes. Data sources include EHR systems, lab results, imaging data, and wearable device information.
Financial Applications
Financial institutions utilize big data for fraud detection, risk management, and customer relationship management (CRM). Transaction data, market trends, and customer behavior are analyzed to identify suspicious activities and mitigate potential risks. Cloud platforms facilitate the rapid processing and analysis of these massive datasets, enabling financial institutions to respond swiftly to emerging threats. Sophisticated algorithms are applied to identify patterns in customer behavior, enabling personalized financial products and services, improving customer experience and loyalty.
Data sources encompass transaction records, market indices, customer profiles, and social media sentiment.
Retail Applications
Retail businesses leverage big data to personalize customer experiences, optimize inventory management, and enhance marketing campaigns. Customer purchase history, browsing behavior, and demographics are analyzed to tailor product recommendations and targeted advertising. Cloud-based platforms provide the necessary infrastructure for processing and analyzing massive amounts of transactional data and customer data. Insights derived from these analyses optimize pricing strategies, inventory levels, and store layouts, leading to improved profitability and customer satisfaction.
Data sources include point-of-sale (POS) data, customer relationship management (CRM) systems, website analytics, and social media interactions.
Comparative Analysis of Big Data Applications
| Application Sector | Data Sources | Data Types | Insights and Business Impact |
|---|---|---|---|
| Healthcare | EHRs, lab results, imaging data, wearable devices | Structured, semi-structured, unstructured | Improved patient care, disease prediction, personalized treatments, optimized resource allocation |
| Finance | Transaction records, market indices, customer profiles, social media sentiment | Structured, semi-structured | Fraud detection, risk management, personalized financial products, improved customer experience |
| Retail | POS data, CRM systems, website analytics, social media interactions | Structured, semi-structured, unstructured | Personalized recommendations, optimized inventory management, targeted advertising, improved profitability |
Wrap-Up
In conclusion, Cloud Computing & Big Data offers a powerful toolkit for managing and extracting value from massive datasets. By understanding the core principles, platforms, technologies, and security considerations, businesses and individuals can leverage this technology to unlock new levels of efficiency, innovation, and insight. The future of data management and analysis is undeniably shaped by these transformative technologies.
Commonly Asked Questions
What are some common security threats associated with cloud computing and big data?
Common security threats include unauthorized access, data breaches, and denial-of-service attacks. Strong encryption, robust access controls, and regular security audits are crucial for mitigating these risks.
How does cloud computing enhance big data processing efficiency?
Cloud computing provides scalable infrastructure that allows for rapid processing of large datasets. This eliminates the need for significant upfront investment in hardware and enables efficient processing and storage of massive amounts of data.
What are the key differences between Hadoop and Spark?
Hadoop is a distributed processing framework that excels at handling massive datasets, while Spark offers faster processing speeds for iterative computations. The choice depends on the specific needs of the data processing task.
What are the ethical considerations related to big data and cloud computing?
Ethical considerations include data privacy, bias in algorithms, and the responsible use of data-driven insights. Transparency and accountability are crucial in ensuring the ethical implementation of these technologies.





